Integrating DataHub with TrendMiner
TrendMiner provides process manufacturing companies the analytical means to further optimize their production processes. The self-service analytics approach allows you to conduct time-series industrial analytics, with data being automatically visualized in displays and dashboards.
For that purpose, TrendMiner accesses industrial data generated by these production processes, resulting in time series of sensor, instrument, and asset data. TrendMiner analyzes these time series in order to identify trends and patterns and derive actionable insights solving production issues.
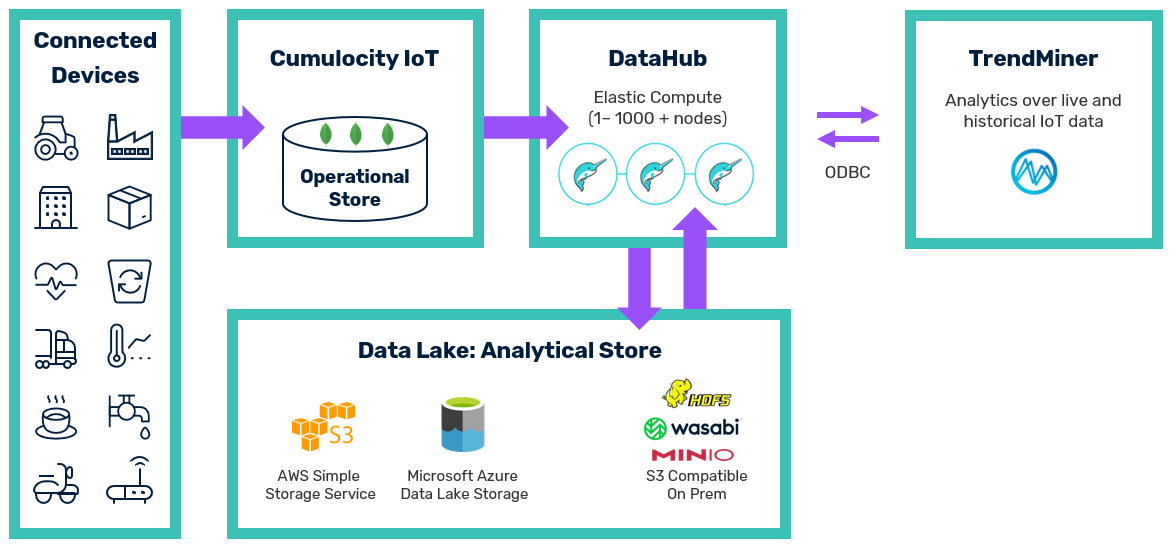
With the offloading and query capabilities of DataHub, TrendMiner can also access and analyze the data being managed by the Cumulocity IoT platform. Key features of the integration between DataHub and TrendMiner are:
- TrendMiner can leverage historical data of the Cumulocity IoT platform without adversely affecting the Operational Store of the platform. DataHub offloads for that purpose the data from the Operational Store to a data lake.
- TrendMiner offers a time-series visualization interface and operational monitoring, both relying on live data from the Cumulocity IoT platform. DataHub provides for that purpose a live view on recent data in the Operational Store of the platform.
- DataHub unifies the data access layer so that TrendMiner can access historical as well as live data by querying a single view.
- DataHub ensures that the layout of that table meets the query needs of TrendMiner, i.e., the data is in a relational and flattened format, not in a document-based format as in the Operational Store.
The following diagram illustrates the high-level concepts of the integration between DataHub and TrendMiner.
Design of a TrendMiner offloading pipeline
Providing TrendMiner access to Cumulocity IoT data requires you solely to define an offloading pipeline using the TrendMiner data layout. When the offloading pipeline is in place, Cumulocity IoT data is regularly extracted from the Operational Store, flattened, and exported into a data lake. In addition, Dremio is configured to access recent data from the Operational Store, using the same schema as for the historical data.
In Dremio a new view is provided, which combines the historical data in the data lake with recent data from the Operational Store, effectively providing a unified view over hot data in the Operational Store and cold data in the data lake. DataHub takes care that the combined data in that view is lossless and does not introduce duplicates. This view is the single connection point to provide TrendMiner access to historical and live data of the Cumulocity IoT platform.
Info: So far DataHub provides TrendMiner acccess to the measurements collection. Other base collections are not yet supported.
You have to follow the instructions in Configuring offloading jobs on how to configure an offloading pipeline for the measurements collection, so that TrendMiner can access the data. This section also provides the schema of the view.
Accessing Cumulocity IoT data in TrendMiner
Once you have defined and activated a TrendMiner offloading pipeline, the initial offload has to be completed before you can start querying the data in TrendMiner.
Warning: The offloading pipeline has to be active. If the pipeline is deactivated, you can only query the contents offloaded into the data lake so far. Access to recent data will be deactivated.
In TrendMiner you have to connect to the Dremio view c8y_cdh_tm_measurements_live using ODBC. For the ODBC connection settings, you have to navigate to the Home page in the DataHub UI and click the ODBC icon to open the ODBC connection settings.
For more details on the steps required in TrendMiner, see also the corresponding TrendMiner documentation of the connector configuration.
Integrating DataHub with Machine Learning Workbench
Machine Learning Workbench (MLW) is designed to facilitate the work of data scientists and machine learning practitioners by streamlining model training and evaluation activities. MLW provides a no-code UI as well as a Jupyter Notebook based setup for the various machine learning tasks.
Machine learning heavily relies on suitable datasets for training and evaluating models. For the specific case of IoT data, MLW offers tooling to ingest and process data from devices connected to the Cumulocity IoT platform. In particular, MLW can process the data which DataHub has offloaded into a data lake. For that purpose, MLW provides a connector for DataHub, which fetches the data from the data lake using a SQL query. The imported data is then stored in CSV format in MLW. Once the data is in place, you can start training or evaluating corresponding machine learning models.
For detailed instructions on how to leverage data offloaded by DataHub in MLW see section Data pull of the MLW documentation.