Cumulocity DataHub overview
This section outlines the structure of the document and gives a high-level introduction into Cumulocity DataHub (CDH) and its concepts.
This section outlines the structure of the document and gives a high-level introduction into Cumulocity DataHub (CDH) and its concepts.
The following sections will walk you through all the functionalities of Cumulocity DataHub in detail.
For your convenience, here is an overview of the contents of this document:
| Section | Content |
|---|---|
| Getting started with Cumulocity DataHub | Log into Cumulocity DataHub and get an overview of the UI features |
| Setting up Cumulocity DataHub | Set up Cumulocity DataHub and its components |
| Working with Cumulocity DataHub | Manage offloading pipelines and query the offloaded results |
| Operating Cumulocity DataHub | Run administrative tasks |
| Running Cumulocity DataHub on Cumulocity Edge | Run the Edge edition of Cumulocity DataHub |
| Integrating Cumulocity DataHub with other products | Learn how to integrate Cumulocity DataHub with other products |
The change log provides an overview on features, changes, and other relevant information.
The Cumulocity platform allows you to manage and monitor a variety of devices. The data emitted by these devices is stored in the Operational Store of Cumulocity, with older data potentially being removed (based on data retention settings). In order to run an ad-hoc query against recent device data, Cumulocity offers a REST API, which is described in the Cumulocity OpenAPI Specification.
In addition to this simple ad-hoc querying, various use cases require more sophisticated analytical querying over the device data, potentially covering long periods of time. Cumulocity DataHub is the tool designed for this purpose.
With Cumulocity DataHub, you can connect existing tools and applications to Cumulocity, such as:
Business Intelligence/reporting tools (using ODBC, JDBC)
Machine learning applications (mainly written in Python using ODBC)
Arbitrary custom applications (using JDBC for Java applications, ODBC for .NET, Python, node.js, and others, or REST for web applications)
The main features of the Cumulocity DataHub application are:
The following diagram illustrates the high-level concepts.
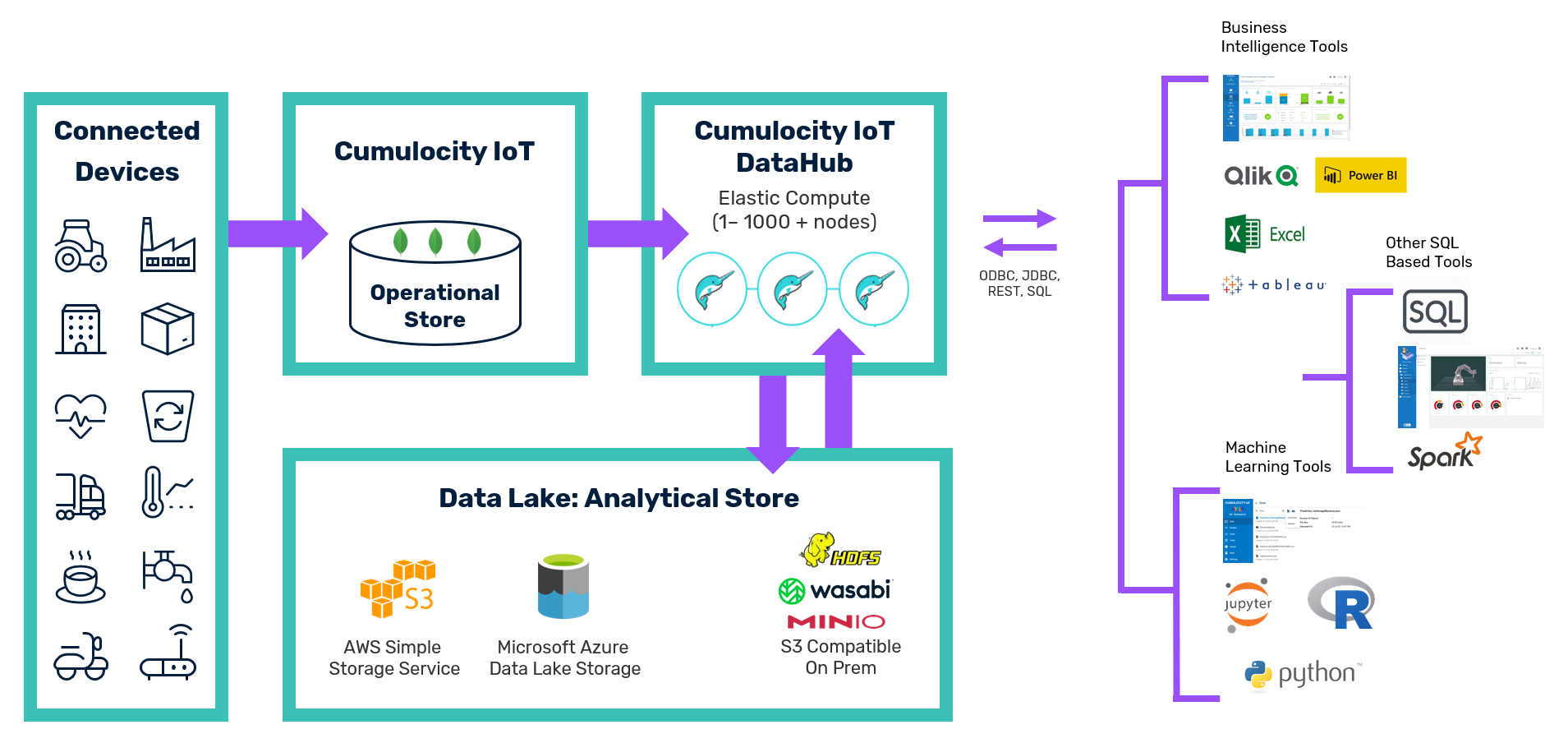
The central component of Cumulocity DataHub is Dremio, a distributed SQL engine that is used for the two purposes mentioned above. It offers an SQL API which can be accessed via JDBC, ODBC, and REST. Dremio is in charge of Extract-Transform-Load (ETL) pipelines that:
When a user submits an SQL query, the query runs against data in the data lake. Thus, the Operational Store of Cumulocity is not accessed during query processing; the Operational Store is only accessed by the regular ETL process which extracts the data. Cumulocity DataHub manages those ETL processes and ensures their execution in a periodic manner.
The table below summarizes the main terms used throughout this documentation.
| Component | Explanation |
|---|---|
| Cumulocity DataHub | Cumulocity application for offloading data from the Operational Store of Cumulocity to a data lake and querying the data lake contents; scheduler component (deployed as microservice) for triggering periodic offloading and UI component (deployed as web application) for defining, managing, and monitoring offloading pipelines |
| Cumulocity Operational Store | Internal datastore of Cumulocity where all data (alarms, events, inventory, measurements, …) is stored in so-called base collections |
| Dremio | Internal SQL engine for extracting data from the Cumulocity Operational Store and writing to and reading from the data lake |
| Data lake | Storage container for offloaded data either on the basis of ADLS Gen2/Azure Storage (Azure), S3 (Amazon), NAS, or HDFS |
Offloading refers to moving data from the Operational Store of Cumulocity to a data lake in order to:
The starting point is one of the Cumulocity base collections, such as the measurements collection, that is to be offloaded into the data lake. Once an offloading pipeline for this collection has been configured and started, a couple of actions take place.
When an offloading job runs, the contents of the collection are offloaded. The document-based entities of the Operational Store of Cumulocity are transformed into a relational format by flattening the entries and mapping them to relational rows.
time, source, id, and type. It transforms them into columns in the data lake table. Furthermore, it automatically transforms the contents of measurement fragments into columns of the table. Non-standard fields can also be offloaded to a limited extent. Configuring offloading jobs provides more details and examples for this transformation.As a result of these extraction and transformation steps, the flattened data is stored in Parquet files in the data lake. Apache Parquet is a column-based storage format which enables compression and efficient data fetching. These Parquet files are managed in a folder structure based on a temporal hierarchy, because analytical queries commonly have a temporal background. For example, compute the average oil pressure of last month. In order to ensure a compact layout of the Parquet files, Cumulocity DataHub also regularly runs a compaction algorithm over these files in the background, which combines multiple smaller files in larger files. As the data is stored in a time-based hierarchical manner in the data lake, Cumulocity DataHub can efficiently prune partitions. In addition, queries can explicitly leverage this temporal structure to increase query performance.
The scheduler of Cumulocity DataHub runs the offloading pipelines in a periodic manner. The UI shows for each pipeline the corresponding schedule. Within each of these pipeline executions, newly arrived data is extracted from the Cumulocity collection and transformed and stored in the same way as described above. These incremental offloading tasks are designed to ensure a loss-free and duplicate-free offloading from the collection. For example, if one offloading execution fails, the next execution will automatically pick up the increments the failed one should have processed.
For each offloading pipeline, a so-called target table is created in Dremio that points to the corresponding data folders in the data lake. When you want to run queries with Dremio against the offloaded data, you must use these target tables.