Working with Cumulocity IoT DataHub
This section describes how to offload data from the Operational Store of Cumulocity IoT to a data lake using Cumulocity IoT DataHub.
This section describes how to offload data from the Operational Store of Cumulocity IoT to a data lake using Cumulocity IoT DataHub.
Cumulocity IoT DataHub provides functionality to configure, manage, and execute offloading pipelines that extract and transform data from the Operational Store of Cumulocity IoT and offload it to a data lake.
You need configuration or administration permissions to work with offloading pipelines. See the section Setting up Cumulocity IoT DataHub > Defining Cumulocity IoT DataHub permissions and roles for details.
| Section | Content |
|---|---|
| Configuring offloading jobs | Configure pipelines for offloading data into a data lake |
| Offloading Cumulocity IoT base collections | Examine the result schemas for offloaded Cumulocity IoT base collections |
| Managing offloading jobs | Schedule and manage offloading pipelines |
| Monitoring offloading jobs | Monitor the results of offloading jobs |
| Monitoring compaction jobs | Monitor the results of compaction jobs |
| Querying offloaded Cumulocity IoT data | Query offloaded Cumulocity IoT data in follow-up applications |
| Refining offloaded Cumulocity IoT data | Use Dremio to refine offloaded Cumulocity IoT data |
| Cumulocity IoT DataHub best practices | Learn more about best practices when working with Cumulocity IoT DataHub |
On the Offloading page you do the offloading management and monitoring tasks:
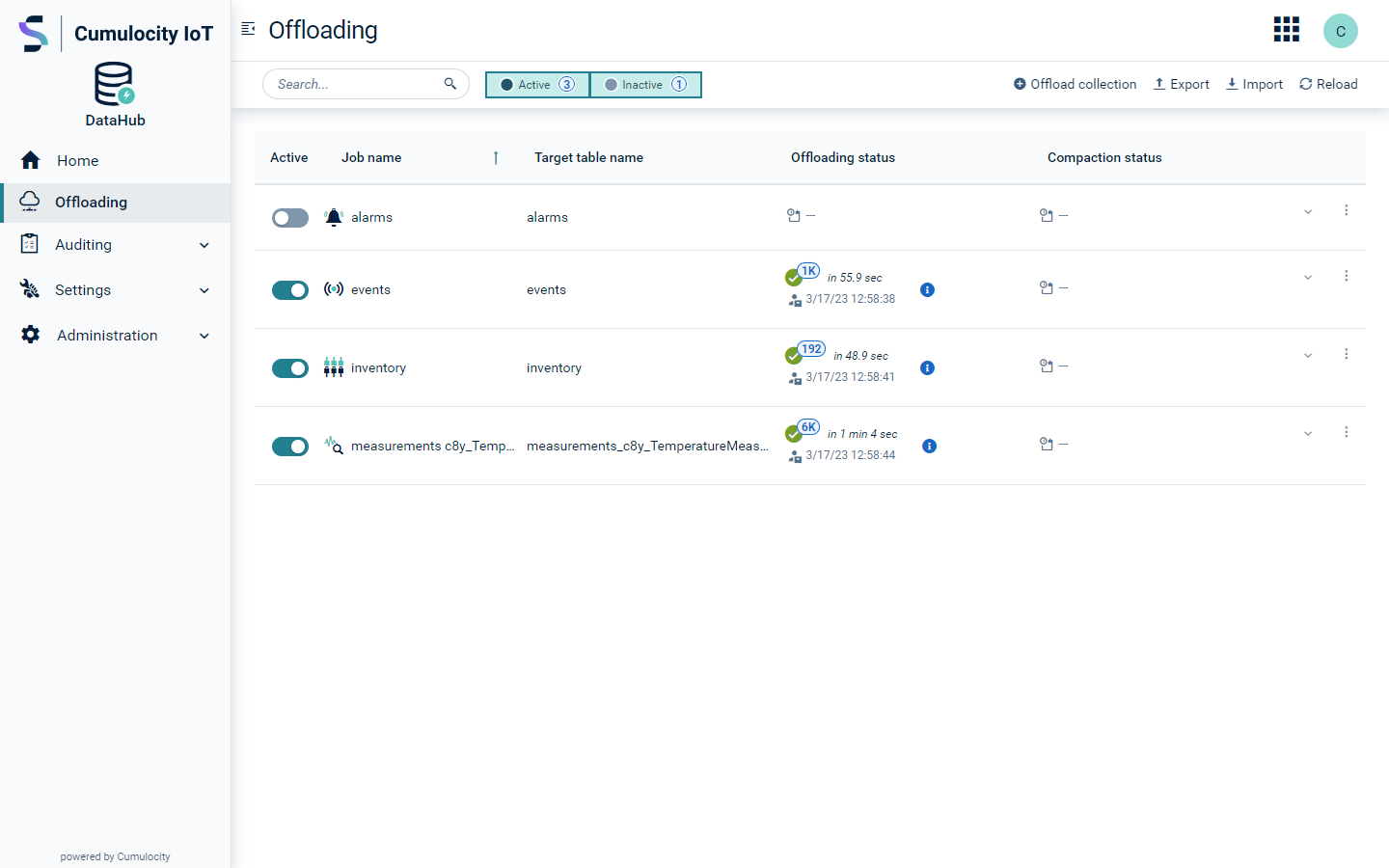
In the main panel of the Offloading page, you will find all pipelines as well as their current status.
In the action bar you have a search field to search for all offloading configurations whose task name, description, filter predicate, additional columns, or UUID contain the search string. You can use the Active/Inactive filter to show/hide configurations being active or inactive respectively. The action bar also provides buttons for adding an offloading configuration, reloading the list of configurations and their status, and importing/exporting configurations.
Below the action bar you find the current list of configurations.
Each offloading configuration provides the following information:
Active
The toggle shows the current job state and can be used to activate or deactivate an offloading job.
Job name
The name of the job refers to the task name as defined in the configuration process. The sort control allows for sorting by job name.
Target table name
The target table name refers to the target table in Dremio, with which the data offloaded by this offloading pipeline can be queried. The sort control allows for sorting by target table name.
Offloading status
The offloading status is empty if the offloading has not been executed yet. If the offloading has been executed, the status of the most recent run is shown. This includes the execution time and whether the execution was successful or not, indicated by a success or failure icon. An additional icon shows whether the execution was scheduled, indicated by a calendar icon, or manually triggered, indicated by a user icon. In case of a successful run, the number of offloaded records and the runtime is shown as well. The sort control allows for sorting by successful/failed jobs. The filter control allows for filtering by execution status.
Compaction status
The compaction status is empty if the offloading has not been executed yet. If the compaction has been executed, the status of the most recent run is shown. This includes the execution time and whether the execution was successful or not, indicated by a success or failure icon. In case of a successful run, the runtime is shown as well. The sort control allows for sorting by successful/failed jobs. The filter control allows for filtering by execution status. The compaction status is only available for users with administration permissions.
Additional information
When expanding a configuration, the job schedule, the additional columns, and the filter predicate are shown as well as additional information. This includes a link that navigates in the Dremio UI to the target table of the pipeline so that you can directly examine the contents of the table. The link is only shown if the pipeline has been executed at least once.
Context menu
In the context menu of a configuration you find controls for managing the offloading process as described in more detail in the next sections.
The following steps describe how to set up an offloading pipeline.
To define an offloading configuration, click Offload collection to start a wizard which guides you through the main steps:
The wizard prepopulates settings for the different steps to ease the configuration process. You can modify those settings according to your needs.
In the dropdown box select one of the Cumulocity IoT base collections, which are:
In the section Offloading Cumulocity IoT base collections you will find a summary of the default attributes being offloaded per base collection.
Click Next to proceed with the next configuration step. Click Cancel to cancel the offloading configuration.
Once you have selected a collection for offloading, you must specify the target table in the data lake. The Target table name denotes the folder name in the data lake. In this folder, which will be automatically created, the offloaded data will be stored. In Dremio a table is created with the same name, pointing to this data lake folder. This table is used when querying the corresponding data lake folder and thus the offloaded data. The target table name must follow these syntax rules:
Each pipeline must have its own target table in the data lake. Thus, you must select distinct target table names for each offloading configuration.
For the alarms, events, and inventory collections, you only need to specify the target table name in this step.
For the measurements collection, additional settings are required. The Target table layout refers to the way the measurements are stored. Measurements in the base collection may have different types. For example, the collection may contain temperature, humidity, and pressure measurements. Depending on your layout choice, measurements are stored differently in the target table.
The layout One table for one measurement type (Default) creates a table containing only measurements of one specific type; measurements of other types are not included. When selecting this layout, you must additionally specify the measurement type to which the offloaded measurements are restricted. To identify existing measurement types, Cumulocity IoT DataHub automatically inspects a subset of the data, including initial as well as latest data. In the measurement type dropdown box, these auto-detected types are listed. If a specific type you are looking for has not been detected, you can manually enter it in this box. Alternatively you can click Refresh next to the dropdown box to manually re-trigger the detection of measurement types. As this might be a performance-intensive process, you should trigger it only if you know that the expected measurement type is present in data recently inserted into the collection. You can trigger such a refresh only every five minutes for performance reasons.
The layout All measurement types in one table (TrendMiner) creates a table containing measurements of all types. To distinguish the measurements, the table has a column which lists for each measurement its corresponding type. The specific table schema for this layout is listed in section Offloading Cumulocity IoT base collections. This layout is only for use cases where you want to offload the data into the data lake, so that TrendMiner can consume the data for its time-series analytics. When this layout is selected, the target table name is set to a fixed, non-editable name, which TrendMiner expects for its data import. To learn more about the interaction between TrendMiner and Cumulocity IoT DataHub, see Integrating Cumulocity IoT DataHub with other products > Integrating Cumulocity IoT DataHub with TrendMiner.
For each base collection, a default set of data fields is derived. This set defines the default schema of the target table with the columns capturing the data fields. The set is fix for each collection and cannot be modified. Select Show default schema to show the columns of the default schema with their corresponding name and type.
Click Next to proceed with the next configuration step. Click Finish to jump directly to the final step. Both steps will fail if the associated base collection is empty, as it prevents necessary schema investigations. In such a case you must ensure that the base collection is not empty before you can proceed with the offloading configuration. Click Previous to go back one configuration step. Click Cancel to cancel the offloading configuration wizard.
If you have added additional top-level fields while feeding data into Cumulocity IoT and you want to access them in your Cumulocity IoT DataHub queries, then you can include them in the offloading process by setting them as additional result columns. You can also use additional result columns to offload data fields in the base collection which are not part of the default schema. Additional result columns can be configured optionally. The TrendMiner case does not support this option.
Auto-detected columns
To ease the configuration process, Cumulocity IoT DataHub auto-detects additional result columns. Using a sample of the base collection, Cumulocity IoT DataHub searches for additional top-level fields and provides them as additional result columns. You can either include such an auto-detected column in your offloading or not. As the auto-detection logic relies on a sample, not all additional top-level fields might be captured. You can manually add a column to include a field you miss.
Structure of additional result columns
Each additional result column, whether it is manually configured or auto-detected, has the following properties:
When entering the configuration step for additional result columns, all columns and their properties are shown in a table, with one additional result column per row. At the top right the Hide auto-detected columns checkbox allows you to either show the auto-detected columns or not. On the right side of each additional result column, a collapse button and a context menu is available. With the collapse button you can expand/collapse more details of the column. In the details section you can explore the source definition as well as sample data of the column. In the context menu of an additional result column you find actions for editing, duplicating, or deleting the column. The column name can also be edited inline by clicking into the name field, adapting the name, and clicking once outside the field.
At the top right of the table you find a button for manually adding an additional result column.
If you enter the additional result columns step for an active offloading pipeline, that is, the pipeline is scheduled, you cannot modify the columns.
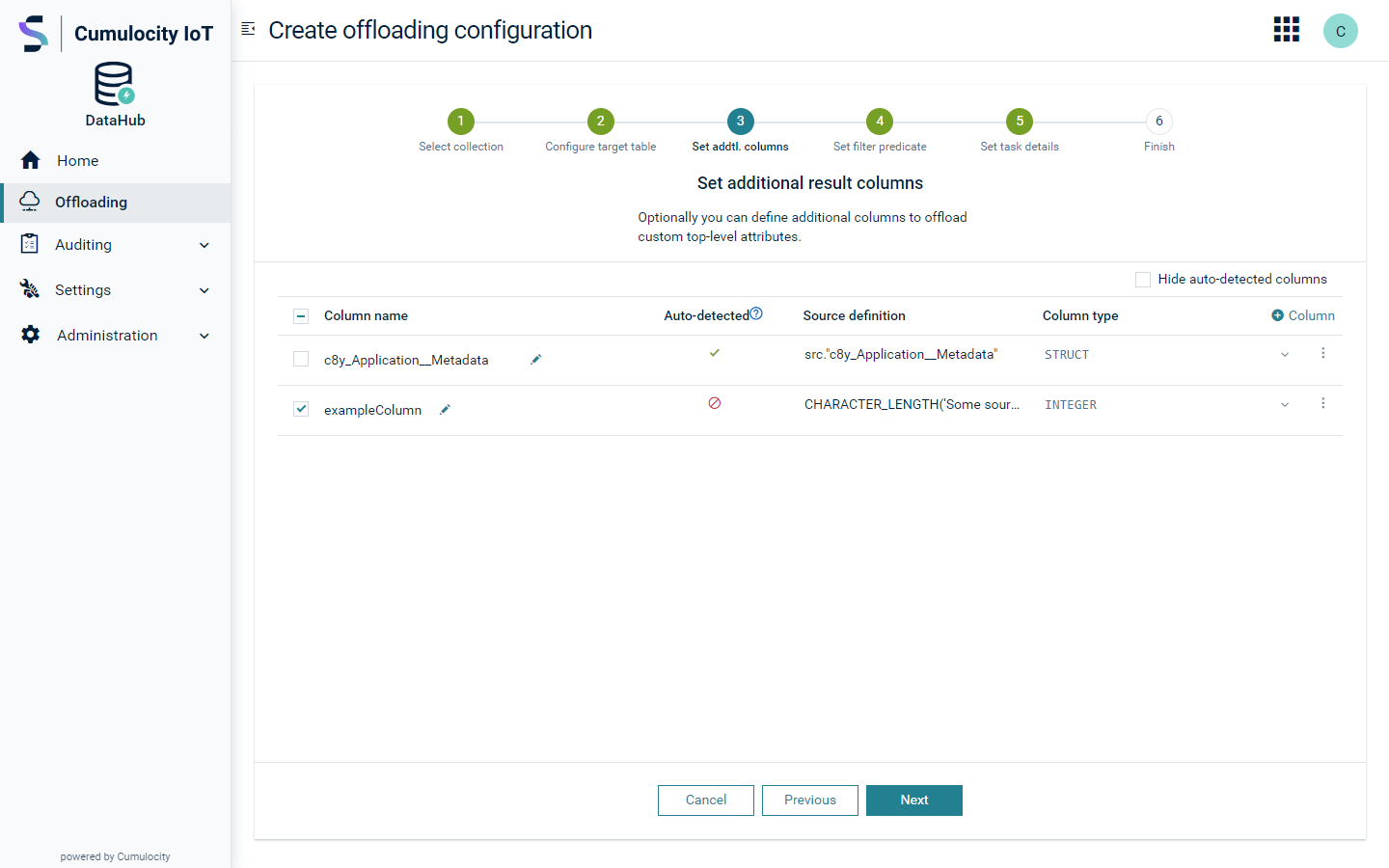
Add an additional result column
When adding an additional result column, a dialog box for defining the column opens. You need to define a unique column name as well as a source definition. You can validate the source definition and preview its results by clicking Validate and preview.
Regarding the source definition, the first step is to specify a field from the base collection in the source definition editor. Then you can optionally apply SQL functions to adapt the data of this field to your needs, for example, by trimming whitespace or rounding decimal values. The source definition editor supports you in this process with content completion and syntax highlighting. The Change data type controls helps you to define a function which changes the data type of the source definition. For example, the source definition is of type VARCHAR and corresponding values are always either true or false. Then you can select Boolean in the Change data type dropdown box to define a function which casts the VARCHAR values to BOOLEAN. Different target data types are available in the control, with some of them having options for dealing with non-matching values. For example, if you want to cast all values to type INTEGER and the non-matching literal N/A is processed, you can configure the casting function to use value 0 instead. If you have selected a data type you want to change to, click Apply to apply or Cancel to revert that type change. Note that functions you can apply to the source definition are not limited to the data type change functions provided under Change data type. In the source definition editor you can apply all SQL functions supported by Dremio, as listed under SQL Function categories.
If you want to derive additional result columns from nested content, you can specify the nested fields using the prefix “src.” and the path to the nested field. For example, if you have a top-level field “someField” with a nested field “someSubField”, add “src.someField.someSubField” as additional result column. In the same way you can access nested arrays. If you have a top-level field “someField” with a nested array field “someArraySubField”, add “src.someField.someArraySubField[0]” as additional result column to access the first array entry.
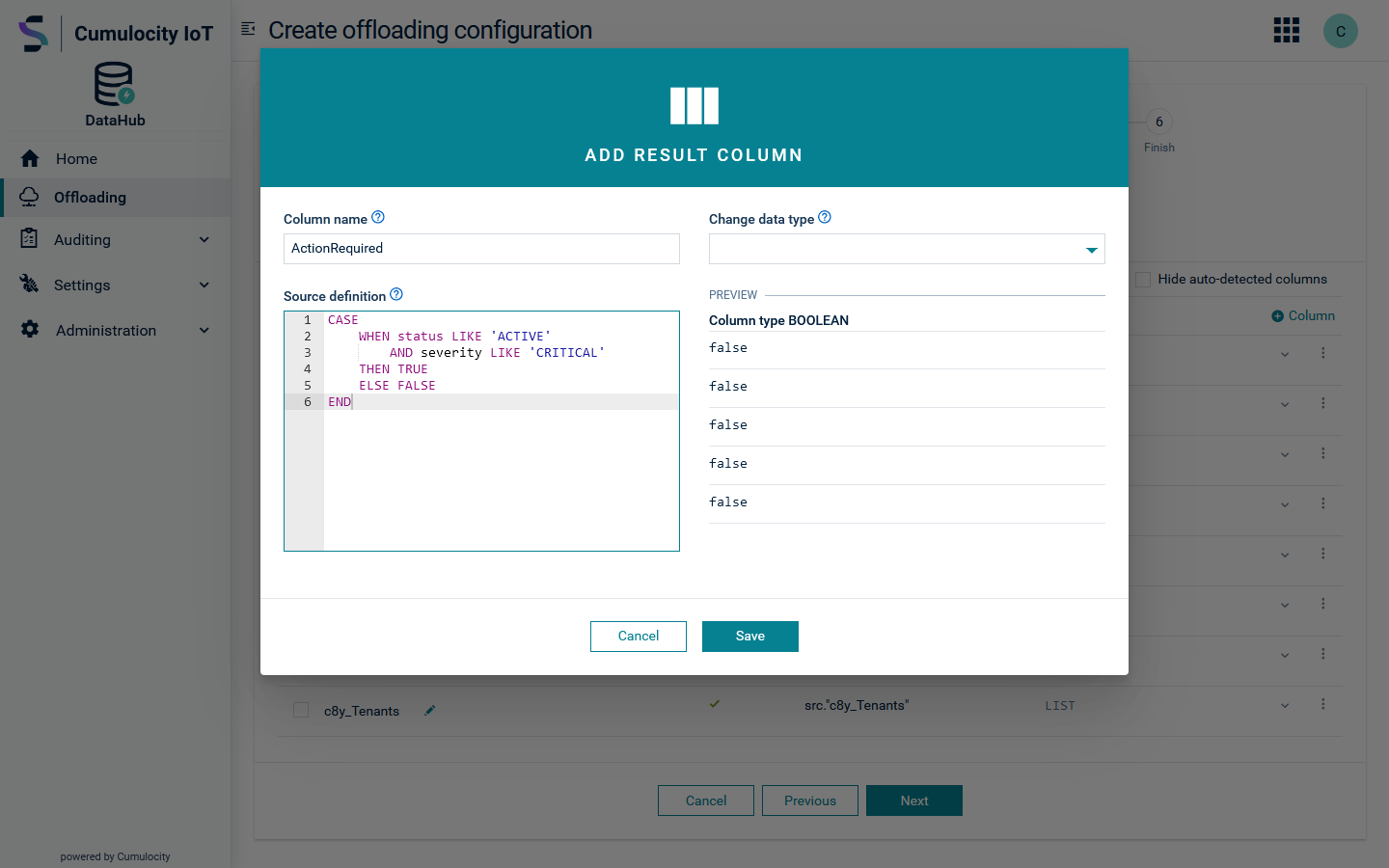
Click Save to add the column, which will be selected for offloading by default. If the source definition is invalid, for example when accessing an unknown column, you get an error message like Column “UnknownColumn” not found in any table. You must fix the source definition before you can proceed. Click Cancel to cancel the configuration of the additional result column.
Edit an additional result column
In the context menu of an additional result column, select Edit to open the dialog for editing the column name and the source definition. Click Save to update the column with the new settings. The column name must be unique and the source definition must be valid in order to proceed. Click Cancel to quit editing the column.
For auto-detected columns the source definition cannot be modified. If you want to modify the source definition, you must duplicate the auto-detected column and modify the source definition as required.
Duplicate an additional result column
In the context menu of an additional result column, select Duplicate to open the dialog for duplicating the column. The source definition of the duplicate column is the same as of the original column and can be adapted to your needs. The new column name initially uses the original column name plus a counter suffix to make the name unique. You can change the name as required. You can also rename the original column. New as well as original column name must be unique.
Click Save to complete and Cancel to quit duplicating the column.
A common use-case for duplication is to change the data type of an auto-detected column. For example, duplicate the column “statusOrdinal” and apply the corresponding casting function in the source definition editor. Use as new column name “statusOrdinal” and rename the original column to “statusOrdinal_Old”. In the additional columns list select “statusOrdinal” and deselect “statusOrdinal_Old”.
Delete an additional result column
In the context menu of an additional result column, select Delete to open the dialog for deleting the column. Click Confirm to proceed or Cancel to cancel the deletion. Auto-detected columns cannot be deleted.
When deleting an additional result column, the data will no longer be included in the next offloading run. Data which has already been offloaded to the data lake is not affected by the deletion of the column. Thus, the column itself will still be present in the data lake, but will have value NULL once the additional result column has been deleted.
Click Next to proceed with the next configuration step. Click Previous to go back one configuration step. Click Cancel to cancel the offloading configuration.
Optionally you can define a filter predicate. Per default, all entries in the base collection are offloaded to the data lake; you can use the predicate to filter out entries you do not want to persist in the data lake. For example, you can filter out invalid values or outliers. In the Additional filter predicate field, you can specify such a filter in SQL syntax. For example, for the alarms collection the filter might be status='ACTIVE' AND severity='WARNING' to only persist active alarms with a severe warning. The filter predicate functionality supports complex SQL statements, that is, a combination of AND/OR, clauses like IN(...) / NOT IN(...), and functions such as REGEXP_LIKE(text, 'MyText\S+').
In the filter predicate you can query all standard attributes of the base collection as well as the custom fields. The additional result columns defined in the previous configuration step cannot be accessed by their name in the filter predicate. You must use the source definition as defined in the corresponding column instead.
id, you must use _id. For examples on querying different attributes, see also DataHub best practices.When defining an additional filter predicate, you can click Validate to validate your predicate. If the validation fails, you will get an error description. You must fix these errors before you can proceed.
Click Next to proceed with the next configuration step. Click Previous to go back one configuration step. Click Cancel to cancel the offloading configuration.
The task configuration step includes the offloading task name and the description. The Offloading task name is an identifier for the offloading pipeline. It must have at minimum one non-whitespace character. Even though the task name does not have to be unique, it is advisable to use a unique name.
In the Description field, you can add a description for this offloading pipeline. The description is optional, but we recommend you to use it, as it provides additional information about the pipeline and its purpose.
Click Next to proceed with the next configuration step. Click Previous to go back one configuration step. Click Cancel to cancel the offloading configuration.
The final step provides a summary of your settings, the configuration of additional settings, and a result preview. The summary includes the settings from the previous steps as well as the internal UUID of this configuration. The UUID is generated by the system and cannot be modified. With the UUID you can distinguish configurations having the same task name, for example, when browsing the audit log or the offloading status. In the summary, you also get the schedule with which the offloading pipeline will be executed once it is started, for example, “every hour at minute 6”. With the Inactive/Active toggle at the end of the summary you select whether the periodic offloading execution should be activated upon save or not.
In the offloading preview you can inspect how the actual data will be stored in the data lake. For this purpose, an offloading preview is executed, returning a sample of the resulting data. The header row of the sample data incorporates the column name as well as the column type. Use Hide time columns to either show the default columns with a temporal notion or not. Note that the preview does not persist data to the data lake.
Offloading frequency
Per default each active offloading pipeline is executed once an hour, at the same minute. You can adapt the offloading frequency by setting in the dropdown box the hours per day at which the offloading will to be executed. As with the default setting, the exact minute of the hour for the execution is selected by the system. The hours are defined with respect to UTC as timezone. You have to select at least one hour; otherwise the configuration cannot be saved.
Compaction strategy
In the additional settings, you can define the compaction strategy for the offloading pipeline. The compaction strategy refers to how Cumulocity IoT DataHub automatically combines multiple smaller files in the data lake into one or more larger files. Cumulocity IoT DataHub periodically executes the compaction for an offloading pipeline as a large number of small files may adversely affect the query performance. The compaction is executed once per day; the compaction schedule cannot be modified.
Cumulocity IoT DataHub automatically sets the compaction strategy, but allows you to optionally change the strategy. Available compaction strategies are:
You can change the compaction strategy of an already running offloading pipeline by deactivating the pipeline, editing the compaction strategy, and reactivating the pipeline. If a compaction was already executed in the past, changing the compaction strategy does not revert the previous compaction results.
View materialization
In the additional settings, you can enable/disable view materialization for an offloading pipeline based on the alarms, events, or inventory collection. For these three collections, additional views over the target table are defined in the tenant’s space in Dremio. The _latest view maintains the latest status of all entities, excluding intermediate transitions of an entity. For large tables, the maintenance of the view might adversely affect overall performance. For that reason, the _latest view can be materialized so that the latest state of each entity will be persisted in the data lake. If that setting is activated for a pipeline, the materialized view will be created with the next offloading run and updated for each subsequent run. The materialized view is named with suffix _c8y_cdh_latest_materialized. If you deactivate the setting for a pipeline, the view is still available, but no more materialized.
Duplicate column names
Another setting, which applies only for the measurements collection, is the handling of duplicate column names. During offloading, measurement values are transformed into a relational format. Corresponding column names of measurement values are constructed by concatenating path and unit/value. This may lead to columns having the same name except for their case. Then the entries would all be offloaded into the same column. As this may be an unwanted behaviour in the offloading process, the names can be sanitized. When activated, for each generated column name, which would be equal to another column name in terms of case-insensitivity, a new column will be created, whose name includes the originally derived name plus a unique suffix.
The following two example documents from two different offloading runs would be processed as follows.
First document:
{
"id": "4711",
...
"time": {
"date": "2020-03-19T00:00:00.000Z",
"offset": 0
},
"type": "c8y_Temperature",
"_seriesValueFragments": [{
"unit": "C",
"value": 17.3,
"path": "c8y_TemperatureMeasurement.T"
}]
}
Second document:
{
"id": "4711",
...
"time": {
"date": "2020-03-20T00:00:00.000Z",
"offset": 0
},
"type": "c8y_Temperature",
"_seriesValueFragments": [{
"unit": "C",
"value": "NaN",
"path": "c8y_temperaturemeasurement.T"
}]
}
The two paths c8y_TemperatureMeasurement.T and c8y_temperaturemeasurement.T are equal in terms of case-insensitivity. Without name sanitization, only the column c8y_TemperatureMeasurement.T.unit will be created, which stores all unit entries. Analogously, one column c8y_TemperatureMeasurement.T.value will be created, which stores all value entries. In the latter case, the column would have a mixed type of DOUBLE and VARCHAR, which Dremio would then coerce to type VARCHAR for the column.
The first time an offloading run processes multiple fragments with the corresponding column names being equal with respect to case-insensitivity, the sanitization also generates distinct column names, with each name having a unique suffix.
Raising alarms
Offloading as well as compaction runs may fail due to various reasons such as network issues, timeouts etc. As described in History per offloading pipeline and History of compactions per offloading pipeline, the offloading and compaction job histories provide details for successful and failed runs. Additionally, an alarm can be raised within the Cumulocity IoT platform in case of a failure. Such an alarm is available in the Cumulocity IoT Device management application.
Under Create alarm on you can activate raising alarms for offloading as well as compaction failures. Per default, the setting is activated for offloading and deactivated for compaction failures. When activated and an offloading run fails, an alarm is raised. If the offloading fails multiple times in a row, the associated alarm is updated with each new failure. The more successive runs fail, the higher the severity of the alarm will be, ranging from warning up to critical. Each alarm comprises information which offloading pipeline has failed and how often it has failed in a row. The same applies to alarms being raised for compaction failures.
The alarm will be active until it is cleared. The latter is the case when either an offloading run completes successfully, or the offloading configuration is deleted. Then, the active alarm is cleared, no matter if the alarms setting is activated or not. The alarm remains active if the offloading is unscheduled or raising alarms is deactivated. Again, the same applies to alarms being raised for compaction failures.
Each offloading pipeline must ensure that the columns of the result table in the data lake have a unique data type each. A mixed type situation occurs if an offloading run detects a data type not matching the expected column data type. For example, the type of a column is INTEGER. Then, the offloading processes the literal N/A, which is of type VARCHAR. To resolve such a mixed type constellation, you can either use the Automatically evolve schema or the Stop pipeline strategy.
Automatically evolve schema: This is the default strategy. The system automatically evolves the schema by introducing a new column for the data with a new type. The name of that column is the original column name plus the new data type as suffix. Each new value will from now on be stored in the new column, having the new type. In the job history of the pipeline the job having detected the mixed type is marked as successful.
Stop pipeline: The system stops the pipeline in order to allow for corrective actions like modifying the data or adapting the additional result columns. After those corrections you must manually re-activate the pipeline. In the job history of the pipeline the job having detected the mixed type is marked as errorneous.
When a mixed type constellation has been detected, an alarm will be additionally raised in the Cumulocity IoT platform with further details like involved column and types. When schema evolution is selected, an alarm of type WARNING is raised. When pipeline stop is selected, an alarm of type CRITICAL is raised. Such an alarm is always raised, independent of the configuration for raising alarms as described in the previous section. The alarm must be manually cleared. It is only automatically cleared if the offloading pipeline is deleted.
For more details on data modeling and mixed types see also section Aligning data modeling and offloading.
Completing the offloading configuration
Finally, click Save to save the offloading pipeline. Otherwise click Cancel to cancel the offloading configuration. You can also navigate back to adapt previous settings, using the Previous buttons.
The following tables summarize the resulting schemas for each of the Cumulocity IoT base collections. These schemas additionally include the virtual columns dir0, …, dir3, which are used for internal purposes. The columns are generated during the extraction process, but neither do they have corresponding data in the Operational Store of Cumulocity IoT, nor are they persisted in the data lake. Do not use dir0, …, dir3 as additional columns or rename them accordingly in your offloading configuration.
The alarm collection keeps track of alarms which have been raised. During offloading, the data of the alarm collection is flattened, with the resulting schema being defined as follows:
| Column name | Column type |
|---|---|
| id | VARCHAR |
| count | INTEGER |
| creationTime | TIMESTAMP |
| creationTimeOffset | INTEGER |
| creationTimeWithOffset | TIMESTAMP |
| lastUpdated | TIMESTAMP |
| lastUpdatedOffset | INTEGER |
| lastUpdatedWithOffset | TIMESTAMP |
| YEAR | VARCHAR |
| MONTH | VARCHAR |
| DAY | VARCHAR |
| time | TIMESTAMP |
| timeOffset | INTEGER |
| timeWithOffset | TIMESTAMP |
| severity | VARCHAR |
| source | VARCHAR |
| status | VARCHAR |
| text | VARCHAR |
| type | VARCHAR |
firstOccurrenceTime is not included in the default schema. If you want to include it in the offloading,
it must be added manually.The alarms collection keeps track of alarms. An alarm may change its status over time. The alarms collection also supports updates to incorporate these changes. Therefore an offloading pipeline for the alarms collection encompasses additional steps:
The views are provided in your Dremio space. For details on views and spaces in Dremio, see the section Working with Cumulocity IoT DataHub > Refining Offloaded Cumulocity IoT Data.
The events collection manages the events. During offloading, the data of the events collection is flattened, with the resulting schema being defined as follows:
| Column name | Column type |
|---|---|
| id | VARCHAR |
| creationTime | TIMESTAMP |
| creationTimeOffset | INTEGER |
| creationTimeWithOffset | TIMESTAMP |
| lastUpdated | TIMESTAMP |
| lastUpdatedOffset | INTEGER |
| lastUpdatedWithOffset | TIMESTAMP |
| YEAR | VARCHAR |
| MONTH | VARCHAR |
| DAY | VARCHAR |
| time | TIMESTAMP |
| timeOffset | INTEGER |
| timeWithOffset | TIMESTAMP |
| source | VARCHAR |
| text | VARCHAR |
| type | VARCHAR |
Events, just like alarms, are mutable, that is, they can be changed after their creation. Thus, the same logic as for alarms applies.
Additional views over the target table are defined in the tenant’s space in Dremio. Their names are defined as target table name plus _all, _latest, and _c8y_cdh_latest_materialized respectively. The following examples use events as target table name:
The views are provided in your Dremio space. For details on views and spaces in Dremio, see the section Working with Cumulocity IoT DataHub > Refining Offloaded Cumulocity IoT Data.
The inventory collection keeps track of managed objects. During offloading, the data of the inventory collection is flattened, with the resulting schema being defined as follows:
| Column name | Column type |
|---|---|
| id | VARCHAR |
| creationTime | TIMESTAMP |
| creationTimeOffset | INTEGER |
| creationTimeWithOffset | TIMESTAMP |
| lastUpdated | TIMESTAMP |
| lastUpdatedOffset | INTEGER |
| lastUpdatedWithOffset | TIMESTAMP |
| YEAR | VARCHAR |
| MONTH | VARCHAR |
| DAY | VARCHAR |
| name | VARCHAR |
| owner | VARCHAR |
| type | VARCHAR |
| c8y_IsDevice | BOOLEAN |
| c8y_IsDeviceGroup | BOOLEAN |
The inventory collection keeps track of managed objects. Note that Cumulocity IoT DataHub automatically filters out internal objects of the Cumulocity IoT platform. These internal objects are also not returned when using the Cumulocity IoT REST API. A managed object may change its state over time. The inventory collection also supports updates to incorporate these changes. Therefore an offloading pipeline for the inventory encompasses additional steps:
The views are provided in your Dremio space. For details on views and spaces in Dremio, see the section Working with Cumulocity IoT DataHub > Refining Offloaded Cumulocity IoT Data.
The measurements collection stores device measurements. Offloading the measurements collection differs from the other collections as you must explicitly select a target table layout, which is either having one table for one type or, for the TrendMiner case, one table with measurements of all types.
When using the default layout, you must select a measurement type, so that all offloaded data is of the same type. During offloading, the data of the measurements collection is flattened, with the resulting schema being defined as follows:
| Column name | Column type |
|---|---|
| id | VARCHAR |
| creationTime | TIMESTAMP |
| creationTimeOffset | INTEGER |
| creationTimeWithOffset | TIMESTAMP |
| YEAR | VARCHAR |
| MONTH | VARCHAR |
| DAY | VARCHAR |
| time | TIMESTAMP |
| timeOffset | INTEGER |
| timeWithOffset | TIMESTAMP |
| source | VARCHAR |
| type | VARCHAR |
| fragment.attribute1.name.value | Depends on data type, often FLOAT |
| fragment.attribute1.name.unit | String |
| … | |
| fragment.attributeN.name.value | Depends on data type, often FLOAT |
| fragment.attributeN.name.unit | String |
| myCustomAttribute1 | Depends on data type |
| … | |
| myCustomAttributeN | Depends on data type |
The entries in the measurements collection can have a different structure, depending on the types of data the corresponding device emits. While one sensor might emit temperature and humidity values, another sensor might emit pressure values. The flattened structure of these attributes is defined as fragment. followed by attribute name and associated type being defined as in the measurements collection. The concrete number of attributes depends on the measurement type, illustrated in the above table with fragment.attribute1.name.value to fragment.attributeN.name.value.
Example
The following excerpt of a measurement document in the base collection is processed as follows:
{
"id": "4711",
...
"time": "2020-03-19T00:00:00.000Z",
"type": "c8y_Temperature",
"c8y_Temperature": {
"T": {
"unit": "C",
"value": 2.079
}
}
}
The system uses the type attribute to determine c8y_Temperature as measurement type. Next it determines the measurement fragment c8y_Temperature, which comprises measurement type T, measurement value 2.079, and measurement unit C as properties. This fragment is flattened and represented in the target table in the data lake as
| … | c8y_Temperature.T.unit | c8y_Temperature.T.value | … |
|---|---|---|---|
| … | C | 2.0791169082 | … |
When using the TrendMiner layout, all measurements are offloaded into one table c8y_cdh_tm_measurements. Their corresponding type is stored in column type. The column unit defines the unit, while the column value defines the value of the measurement. The column tagname is used by TrendMiner to search for specific series. It is composed of the source, the fragment, and the series as stored in the measurements collection.
The resulting schema is defined as follows:
| Column name | Column type |
|---|---|
| id | VARCHAR |
| creationTime | TIMESTAMP |
| creationTimeOffset | INTEGER |
| creationTimeWithOffset | TIMESTAMP |
| time | TIMESTAMP |
| timeOffset | INTEGER |
| timeWithOffset | TIMESTAMP |
| YEAR | VARCHAR |
| MONTH | VARCHAR |
| DAY | VARCHAR |
| source | VARCHAR |
| type | VARCHAR |
| tagname | VARCHAR |
| value | VARCHAR |
| unit | VARCHAR |
Example mapping
The following excerpt of a measurement document in the base collection
{
...
"source": "857",
"type": "Temperature",
...
"c8y_Temperature": {
"T": {
"unit": "C",
"value": 2.0791169082
}
}
}
...
{
...
"source": "311",
"type": "Pressure",
...
"c8y_Pressure": {
"P": {
"unit": "kPa",
"value": 98.0665
}
}
}
is represented in the target table in the data lake as
| … | type | tagname | unit | value | … |
|---|---|---|---|---|---|
| … | Temperature | 857.c8y_TemperatureMeasurement.T | C | 2.0791169082 | … |
| … | Pressure | 311.c8y_PressureMeasurement.P | kPa | 98.0665 | … |
In addition to the table c8y_cdh_tm_measurements, the table c8y_cdh_tm_tags is created. This table stores the tag names and the source IDs, which connect the tagname used in TrendMiner with a device and its ID as managed in the Cumulocity IoT platform. The schema of the c8y_cdh_tm_tags table is defined as:
| Column name | Column type |
|---|---|
| source | VARCHAR |
| tagname | VARCHAR |
| unit | VARCHAR |
| datatype | VARCHAR |
| latestCreationTime | TIMESTAMP |
For more details on the interaction of TrendMiner and Cumulocity IoT DataHub see also Integrating Cumulocity IoT DataHub with other products > Integrating Cumulocity IoT DataHub with TrendMiner.
Cumulocity IoT DataHub allows to offload data from the Cumulocity IoT platform into a data lake and the subsequent analysis of the offloaded data using SQL. For that purpose, Cumulocity IoT DataHub must transform the data from the document-based format into a relational format, which is then persisted as Parquet files in the data lake.
When the offloading is configured, data from the documents in the operational database of the Cumulocity IoT platform is transformed and stored in columns of the target table in the data lake. The system either automatically generates those transformations or proposes them to the user with the option to modify them. The user can also configure additional transformations. A configuration defining how a data field is transformed into a column comprises:
For built-in data attributes specified by the platform, the type is fixed and known to Cumulocity IoT DataHub. For other attributes Cumulocity IoT DataHub determines the type by evaluating the aforementioned expression on the data stored in the operational database. Dremio either does this based on the database state at configuration time or on metadata captured earlier. For performance reasons, the evaluation is based on a subset of data, namely the first 4095 documents of the collection. When evaluating the expression and all instances of the attributes have the same type, this type defines the column type.
If instances of the attribute have diverging types, then the system can apply a type coercion mechanism to resolve such a mixed type constellation. The coercion mechanism derives a single, suitable type from the diverging types. For example, INTEGER and FLOAT are coerced to FLOAT while TIMESTAMP and VARCHAR are coerced to VARCHAR. You can configure how to deal with mixed types for each offloading pipeline. By default the system automatically resolves the mixed type by evolving the schema. That schema evolution uses the type coercion to introduce a new column with the coerced type. Alternatively the system stops the pipeline to allow for corrections. Section Dealing with mixed types describes how to configure those strategies.
The offloading configuration mechanisms differ when dealing with series-value fragments of measurements. As additional fragments are often added dynamically, Cumulocity IoT DataHub automatically picks up each series at runtime without the need to reconfigure the offloading pipeline.
Each series must have a mandatory value of type NUMBER and an optional unit of type STRING. If the value is not of type NUMBER, Cumulocity IoT DataHub determines a type for each series at offloading runtime. It evaluates the runtime type of each value and derives the column type for the corresponding offloading run. If all values for a series can be cast to BOOLEAN, FLOAT, STRUCT or LIST consistently, this will be the type of the resulting column. Otherwise, DataHub will use VARCHAR. If the use case mixes types for the same series, the aforementioned mixed type handling applies.
When modelling your data, take the following guidelines into account:
Description |
|---|
| The data type of an attribute should be static as otherwise mixed type constellations may occur. |
| When modelling measurements and large volumes of them are likely to be generated, leverage the time series data model. When using this model, the offloading and query performance is typically better compared to the default data model. |
| When modelling measurements, you should separate the measurements by specifying measurement types. Then each measurement type can be modeled within a separate offloading pipeline, which in turn leads to a cleaner data architecture in the data lake as well as better query performance. |
| Avoid offloading lists with many entries as this leads to broad tables in the data lake. |
| Avoid having a large number of columns in the data lake as this adversely affects query performance and complicates data access in follow-up applications. |
| When defining attribute names in your data model, avoid special characters in attribute names. The attribute names are used as column names in the resulting offloading table and special characters may hinder working with those columns in follow-up applications. |
| When modelling data within arrays, ensure that the position of the values within the array is fix throughout the documents being fed into the platform. Otherwise further processing might run into problems. |
When modeling your data, you have to be aware of the following limitations:
Description |
|---|
| If two attribute names in a document only differ by case, only one of the values will be used. |
| If the collection to be offloaded has JSON attributes consisting of more than 32,000 characters, its data cannot be offloaded. One specific case where this limitation applies is the Cumulocity IoT application builder, which stores its assets in the inventory collection when being used. |
| If the collection to be offloaded has more than 800 JSON attributes, its data cannot be offloaded. This limitation also includes nested JSON content, which will be expanded into columns during offloading. Therefore, measurements documents with more than 800 series/series value fragments are not supported. |
The following steps describe how to start and manage an offloading pipeline.
Once you have defined an offloading configuration and saved it, you can start the offloading pipeline.
Click the Active toggle in an offloading configuration to activate the periodic execution of the offloading pipeline, if it was not already activated when configuring the pipeline. The scheduler component of Cumulocity IoT DataHub will then periodically trigger the pipeline.
The initial offload denotes the first execution of an offloading pipeline. While subsequent executions only offload data increments, the initial offload moves all collection data from the Operational Store of Cumulocity IoT to the data lake. Thus, the initial offload may need to deal with vast amounts of data. For this reason, the initial offload does not process one big data set, but instead partitions the data into batches and processes the batches. If the initial offload fails, for example due to a data lake outage, the next offload checks which batches were already completed and continues with those not yet completed.
If the same pipeline has already been started and stopped in the past, a new start of the pipeline opens a dialog asking you whether you want to flush the existing data or append the data to the existing data. The latter option offloads only data that has been added after the last execution. The first option flushes the data lake. Then the next execution will offload the complete collection. This option should be used with caution as data deleted in the data lake cannot be recovered.
Before restarting the periodic offloading, you may have changed the result schema by adding or removing columns (via adding or removing additional result columns). When you restart the pipeline, existing data in the data lake is not modified, but the new data being offloaded incorporates the new schema. When querying such a data set comprising different schemas, the system computes a merged schema and (virtually) fills it up with null values where fields have not yet been provided. This usually works without problems if additional attributes are included or removed from the offloading configuration. However, schema merging might fail or lead to unexpected behavior in certain cases. One example is if you change data types, for example, if the old configuration contained “myCustomField1” as a string and you change it to a number via “CAST(myCustomField1 AS Integer) AS myCustomField1”. Therefore you should take care that the data you offload is consistent.
A previous offloading pipeline may have already written into the same target table, that is, the data is stored in the same folder on the data lake. In this case, when starting the new offloading pipeline, you are asked whether you want to flush the existing data or append the data to the existing data. You should only append the data if old and new data share the same schema. Otherwise, you might end up with a table consisting of disparate data, which hinders meaningful analysis. If the new data differs from the old data, you should use a new target table. Alternatively, you can flush the existing table if its old content is not needed anymore. Again, you should be careful when flushing a table as the data most likely cannot be recovered.
The scheduler is configured per default to run the offloading pipeline once an hour. The precise minute of the hour at which the offloading starts is assigned by the system to balance the load on the Operational Store of Cumulocity IoT, that is, to avoid that all offloading jobs from different tenants run at the same time.
Use the Active toggle in an offloading configuration to stop the periodic offloading. Then the scheduler stops scheduling new jobs; currently running jobs will complete.
In the context menu of each offloading pipeline, you will find actions for managing and monitoring the pipeline.
Click Edit to edit the current settings. Only inactive pipelines can be edited. Note that you cannot change the Cumulocity IoT base collection selected for this pipeline. For the measurements collection, the target table layout cannot be changed as well. Additional filter predicates and additional result columns can be changed. Note that these changes are not applied to already exported data. A change to the offloading pipeline only affects data to be exported in upcoming offloading runs.
For active pipelines, click Show to browse through the configuration. You cannot edit the settings.
Click Copy to copy the current configuration. The new configuration is an identical copy of the selected configuration except for the task name and the target table, both of which will have a unique suffix appended. You can change the settings according to your needs.
A TrendMiner offloading configuration cannot be copied, as only one TrendMiner configuration is allowed.
Click Delete to delete a configuration. Only inactive pipelines can be deleted. Data in the data lake which has already been exported by this offloading pipeline is not deleted. To delete the actual data in your data lake, you must use the tooling offered by the data lake provider such as AWS S3 Console or Azure Storage Explorer.
If the periodic offloading is enabled, you can also manually trigger an offloading job between two scheduled executions. For example, you might not want to wait for the next scheduled execution to offload recent data into the data lake. Click Offload now to trigger a manual offloading. As with periodic offloading, a manual offloading execution processes only incremental data that has been added since the last offloading execution (independent of whether this last execution was triggered manually or by the scheduler).
However, we recommend you to rely on the periodic offloading instead of triggering it manually.
Click Show offloading history to examine the execution history of a pipeline. See the section Monitoring offloading jobs for details.
The import/export functionality allows you to backup your offloading configurations to a file. You can use the backup when editing the data lake settings or to copy offloading configurations from one Cumulocity IoT DataHub instance to another. Import/export solely includes the configuration of a pipeline; it includes neither the runtime status of a pipeline nor already exported data.
The action bar provides an Export button, which exports all offloading configurations. The button is disabled if no offloading configurations are defined. If you click Export, all offloading configurations are exported into a file. The file is located in the local download folder used by your browser.
The action bar provides an Import button, which imports offloading configurations from a file with previously exported configurations.
Click Import to open the import dialog. Either drop the file in the import canvas or click into the canvas to browse your file system to select the import file. Once the file is selected, a table with all configurations in the file is shown. For each entry, the table lists the task name, the internal ID of the original configuration, the target table name, and the description. The Status column indicates whether an offloading configuration can be imported. If it is green, the configuration is valid and can be imported. If it is yellow, the configuration can be imported, but some of its settings are ignored as they are not supported by the tenant. If it is red, the configuration duplicates an existing configuration and therefore cannot be imported. It is a duplicate if an existing configuration has the same target table name or the same internal ID. The Import column provides checkboxes to select the configurations which are to be imported.
To import the selected configurations, click Import. Click Cancel to cancel the import process.
As the export does not include whether a configuration was active, you must manually activate the configurations after an import.
Once you have configured and started your offloading pipelines, they regularly offload data to the data lake. The Cumulocity IoT DataHub UI provides insights into the execution status of the different pipelines so that you can investigate whether everything is running as expected. For the case of offloading failures, you can also configure the offloading pipeline to raise an alarm as described in Configuring offloading jobs > Raising alarms.
If you want to examine the execution history for a particular pipeline, select Offloading in the navigation bar and select the one you are interested in.
Click Show offloading history in the context menu of the offloading configuration to show the history of offloading executions.
The list shows the execution history, with each execution consisting of the following details:
| Component | Description |
|---|---|
| Status icon | The status of the execution, which is either running, successful, or error |
| Execution mode icon | The type of execution, which is either scheduled (calendar icon) or manual (user icon) |
| Records | The number of records which have been offloaded during this execution |
| Execution time | The point in time the execution was started |
| Runtime (s) | The runtime of the execution in seconds |
| Next execution time | The point in time for which the next execution is scheduled, provided offloading is activated; for a manual execution it is empty |
The system is configured to keep a limited history of the last job executions.
Click Reload to refresh the list.
You can filter the entries by their status or timestamp by using the filter controls at the top. Click Apply to filter entries with the current filter settings. Click Reset filter to reset the current filter settings.
The page navigation buttons at the bottom can be used to traverse the history entries.
For a given offloading job, you can examine additional details of its execution.
In the corresponding list of jobs click on the job you are specifically interested in. A details view encompasses the following information:
Execution schedule
| Component | Description |
|---|---|
| Runtime (s) | The runtime of the execution in seconds |
| Execution mode | The mode of the execution, which is either manual or scheduled |
| Execution time | The point in time the execution was started |
| Scheduled execution time | The point in time for which the execution was scheduled |
| Previous execution time | The point in time the previous execution was started; for a manual execution it is empty |
| Next execution time | The point in time for which the next execution is scheduled, provided offloading is activated; for a manual execution it is empty |
Results
| Component | Description |
|---|---|
| Records | The number of records which have been offloaded during this execution |
Job details
| Component | Description |
|---|---|
| Job name | The name of the pipeline |
| Job ID | The internal ID of the job |
| Job execution ID | The Dremio ID of this execution |
| Source collection | The name of the Cumulocity IoT base collection |
| Target table | The folder name in the data lake |
| Target folder | The path to the target table in the data lake |
| Last watermark | The last watermark which indicates the data in the Cumulocity IoT collection that has already been processed |
| Data model | The data model, which is either Time series or Standard, used for a measurements offloading; only available for measuremement pipelines |
Offloading results
During offloading Dremio organizes the data in newly created files within the data lake, following a temporal folder hierarchy. For each of those files the following information is provided:
| Component | Description |
|---|---|
| File size | The size of the file |
| Fragment | The hierarchical ID of the fragment |
| Partition | The partition with which the file is associated |
| Path | The path to the file in the data lake |
| Records | The number of records stored in the file |
During offloading, data from the Operational Store of Cumulocity IoT is written into files in the data lake. In order to ensure a compact physical layout of those files, Cumulocity IoT DataHub automatically runs periodic compaction jobs in the background. For each offloading pipeline, a corresponding compaction job is set up and scheduled. Cumulocity IoT DataHub UI provides insights into the compaction status of the different pipelines so that you can investigate whether everything is running as expected. For the case of compaction failures, you can also configure the offloading pipeline to raise an alarm as described in Configuring offloading jobs > Raising alarms.
In the navigator, select Compaction status under Administration to get an overview of the latest status of the compaction jobs for each pipeline. The list shows the corresponding last compaction job for all pipelines. Each compaction consists of the following details:
| Component | Description |
|---|---|
| Status icon | The status of the execution, which is either running, successful, or failed |
| Execution time | The point in time the execution was started |
| Runtime (s) | The runtime of the execution in seconds |
| Next execution time | The point in time for which the next execution is scheduled |
Click Reload to refresh the status being shown.
You can filter the entries by their status by using the filter buttons in the action bar. The pagination buttons can be used to traverse the history entries.
If you want to examine the compaction history for a particular offloading pipeline, select Offloading in the navigation bar and select the offloading job you are interested in.
Click Show compaction history in the context menu of the offloading configuration to show the compaction history.
The list shows the execution history with each execution consisting of the following details:
| Component | Description |
|---|---|
| Status icon | The status of the execution, which is either running, successful, or failed |
| Execution time | The point in time the execution was started |
| Runtime (s) | The runtime of the execution in seconds |
| Next execution time | The point in time for which the next execution is scheduled |
The system is configured to keep a limited history of the last compaction jobs.
Click Reload to refresh the list.
You can filter the entries by their status or timestamp by using the filter controls at the top.
For a given compaction job, you can examine additional details of its execution.
In the corresponding list of jobs click on the job you are specifically interested in. A details view encompasses the following information:
Execution schedule
| Component | Description |
|---|---|
| Runtime (s) | The runtime of the execution in seconds |
| Execution time | The point in time the execution was started |
| Scheduled execution time | The point in time for which the execution was scheduled |
| Next execution time | The point in time for which the next execution is scheduled |
Job details
| Component | Description |
|---|---|
| Job name | The name of the pipeline |
| Job ID | The internal ID of the job |
| Job execution ID | The Dremio ID of this execution |
| Target table | The folder name in the data lake |
| Target folder | The path to the target table in the data lake |
| Daily run | Indicates whether the job is a daily execution job |
| Monthly run | Indicates whether the job is is a monthly execution job |
| Recovery executed | Indicates whether the job has run a recovery from a job that has previously failed |
Daily compaction results
During daily compaction the files are merged, following a temporal hierarchy. As a result, a folder for each day of the month is built with one or more file(s) combining all values measured for this day. For each of those files the following information is provided:
| Component | Description |
|---|---|
| File size | The size of the file |
| Fragment | The hierarchical ID of the fragment |
| Partition | The partition with which the file is associated |
| Path | The path to the file in the data lake |
| Records | The number of records stored in the file |
Monthly compaction results
During monthly compaction the files are merged, following a temporal hierarchy. As a result, a folder for each month is built with one or more file(s) combining all values measured for this month. For each of those files the following information is provided:
| Component | Description |
|---|---|
| File size | The size of the file |
| Fragment | The hierarchical ID of the fragment |
| Partition | The partition with which the file is associated |
| Path | The path to the file in the data lake |
| Records | The number of records stored in the file |
Cumulocity IoT DataHub offers an SQL interface so that you can efficiently query offloaded device data and leverage the results in your own applications. A prerequisite for running SQL queries over device data is that you have configured and executed offloading pipelines that replicate and transform data from the Operational Store of Cumulocity IoT to the data lake.
As described in section Cumulocity IoT DataHub overview > Cumulocity IoT DataHub at a glance, Cumulocity IoT DataHub manages offloading pipelines which periodically extract data from the Operational Store of Cumulocity IoT, transform the data into a relational format, and finally store it in a data lake. Instead of querying the Operational Store, you run your queries against the data lake. The distributed SQL engine Dremio provides the query interfaces to access the data lake.
Different standard interfaces exist for that purpose, namely JDBC, ODBC, and REST. You can also use the Dremio UI. In order to work with one of those interfaces, select Home in the navigation bar. Under Quick links you will find starting points for the different interfaces.
You need a separate Dremio account to run SQL queries. The Dremio account is required to authenticate your requests when running queries against the data lake using Dremio. In the initial configuration step, a corresponding Dremio user has been created. Contact the administrator for the Dremio account settings.
When you have established a connection, you can run SQL queries against your tables in the data lake (to which new data is appended whenever the offloading pipeline has successfully run). The source you refer to in the query is defined by your tenant ID and the target table you have specified in the offloading configuration. The identifier to be used as the source in a SQL query is defined as follows for the different data lake providers:
FileSystem.YourAccountName.TargetTableName with FileSystem denoting the file system within your Azure Storage accountBucket.YourAccountName.TargetTableName with Bucket denoting the bucket within your Amazon S3 accountFor example, if your tenant ID is t47110815 and you have defined an offloading configuration to write the alarms collection to the target table JohnsAlarms in an Azure Storage account containing a file system named Dremio, then an example query would be:
SELECT * FROM t47110815DataLake.Dremio.t47110815.JohnsAlarms;
You can easily look up the paths to the tables in Dremio’s UI. Click on your data lake under “Sources” at the left, then navigate to the table in the right canvas. When you hover over the table name, a small “copy” icon with the tool tip “Copy Path” will appear right of the table name. Clicking on it will copy the table name into your clipboard.
You can use the Dremio UI to interactively run queries against the data lake. See the section Refining offloaded Cumulocity IoT data for more details.
If you have a Java client, you can use JDBC to run SQL queries against the data lake. You must download the Dremio JDBC driver. You can obtain the JDBC connection string and the required driver version from Cumulocity IoT DataHub by clicking the JDBC icon in the Quick links section of the Home page. When setting up your JDBC client, use as username and password the credentials from your Dremio account.
If you want to use an ODBC client to run SQL queries against the data lake, you must configure the platform-specific driver, following the associated Dremio installation instructions. To obtain the ODBC connection string, click the ODBC icon in the Quick links section of the Home page. When setting up your ODBC client use as username and password the credentials from your Dremio account.
Dremio offers an SQL REST API which you can use to run SQL queries against tables in the data lake. You must authenticate with your Dremio account against Dremio in order to use the API.
Note that the API might change any time and Software AG does not provide any guarantees. Dremio does not send any CORS headers, so direct access from a browser-based application is not possible. It is highly recommended to use Cumulocity IoT DataHub’s REST API, see below.
The Cumulocity IoT DataHub server also can handle REST requests for Dremio query processing, serving as a proxy to Dremio. Cumulocity IoT DataHub offers two REST APIs for running queries against Dremio. The standard REST API for small to moderate query result sizes and a high-performance REST API for large query result sizes. See the Cumulocity IoT DataHub REST API documentation in the Cumulocity IoT OpenAPI specification for details on the endpoints. When using this API, you authenticate with your Cumulocity IoT account, not with your Dremio account.
Dremio offers support for connecting a variety of clients, including reporting tools like PowerBI and common analytics languages like Python. The Dremio documentation discusses how to connect these clients to Dremio and leverage its query capabilities.
See also Integrating Cumulocity IoT DataHub with other products to learn how other products can connect to Cumulocity IoT DataHub and leverage its query capabilities.
In addition to SQL querying using standard interfaces, you can utilize Dremio functionality to further refine and curate your offloaded data.
For a detailed description of all functionalities Dremio provides you can consult the Dremio documentation.
You access Dremio via a web browser. It has been tested with the following web browsers:
To access Dremio, navigate to the home page. Under Quick links click on the Dremio icon. This will direct you to the Login screen of Dremio.
On the Login screen, enter your Dremio account credentials. Click Login to enter Dremio.
When you log in successfully, you will be taken to the home page of Dremio.
When you want to log out, click on your username and select Log out.
On the home page of Dremio you will find at the left under Datasets two panels called Spaces and Sources.
In the Sources panel there is the data source YourTenantIdDataLake, for example, t47110815DataLake. This source has been auto-configured for you and points to your data lake.
When you click on your data source it will be shown in the main panel. Clicking on the source in the main panel navigates into the data source. Here, you see a list of all target tables of your offloading pipelines. Clicking one of these target tables opens an SQL editor which allows you to run queries against that target table.
A space in Dremio helps in organizing your data sets. Cumulocity IoT DataHub auto-configures a space which is named YourTenantIdSpace, for example, t47110815Space. A dataset in the space is referred to in queries as YourTenantIdSpace.YourDataset. As described in section Working with Cumulocity IoT DataHub > Offloading Cumulocity IoT base collections, for the inventory, events, and alarms collections there are preconfigured views providing either all or latest data.
The Job History tab displays jobs/queries you have executed. It allows you to view details of a job and offers filter capabilities (time range, job status, query type, and queue). The Profile view inside the job detail view is very useful to investigate optimization potentials in your queries.
With Cumulocity IoT DataHub, you can replicate data from a Cumulocity IoT collection to a data lake using a default transformation of the data. As requirements for subsequent data analysis of the offloaded device data may vary over time, you should configure your offloading pipeline so that all potentially relevant data is included.
Depending on your use cases, you will often find the need to provide a view on the data, which limits, filters, or transforms the data, such as converting Celsius to Fahrenheit or extracting data from JSON fragments.
In Dremio, you can create such a view by defining a corresponding query and saving it as a new dataset. When saving that new dataset, you must select your space as the location and can freely select a name for the view. Once that is done, you can work with the new dataset as with any other source and run queries against it. This includes in particular querying this view from other clients as described in section Working with Cumulocity IoT DataHub > Querying offloaded Cumulocity IoT Data.
Consider the case that you want to visualize data in a reporting tool. The raw data volume is too high, so you want to instead show the hourly average of the column myValue. You can easily do that by creating a view with the following SQL statement and saving it as a view/virtual data set:
SELECT DATE_TRUNC('HOUR', "time") AS "time", AVG(myValue) AS hourlyAvg
FROM myTable
GROUP BY DATE_TRUNC('HOUR', "time")
The creation (and update) of views can be done via the Dremio SQL API, too. This is especially useful to automate tasks. The above example can be created or updated as follows.
CREATE OR REPLACE VDS YourTenantIdSpace.YourDesiredViewName AS
SELECT DATE_TRUNC('HOUR', "time") AS "time", AVG(myValue) AS hourlyAvg
FROM myTable
GROUP BY DATE_TRUNC('HOUR', "time")
Views you have defined and target tables from your data lake can be joined as well. In Dremio you can either define joins using the SQL editor or a graphical interface.
A general use case for joining is to enrich your alarms, events, or measurement values with metadata from the inventory collection, for example:
SELECT *
FROM t47110815DataLake.Dremio.t47110815.alarms
JOIN t47110815DataLake.Dremio.t47110815.inventory
USING(id)
Learn from well-established usage patterns in order to ensure a robust and scalable processing of your SQL queries.
When defining an offloading configuration, you must specify the task name, the target table, and a description. You should ensure that you provide reasonable names for each of these settings so that afterwards you can easily find the offloading pipelines you are interested in. A reasonable naming scheme also facilitates writing queries.
Also when defining an offloading configuration, you must always define a target table that is unique among the currently saved configurations. You should not re-use a target table from an old offloading configuration which was deleted in the meantime. Otherwise, you might run into the problem that your target table consists of data from multiple configurations with potentially different schemas.
An offloading configuration allows you to specify additional columns to be offloaded as well as filter predicates for filtering the data. For both settings, you should carefully think about which data you actually need for your processing. Data being filtered out cannot be retrieved any more. Even if you adapt the filter predicate afterwards, the data which would have qualified in previous offloading executions will not be offloaded. You can, however, stop an offloading, change the configuration to include additional fields, and so on, and then restart it. When it is restarted, Cumulocity IoT DataHub will ask you whether you want to flush existing data or append. Flushing will delete all data in the data lake so that with the next offloading execution the complete collection will be offloaded again. Note that Cumulocity IoT DataHub can only import data that is still present in the Operational Store of Cumulocity IoT, that means, be careful with this option and keep in mind that data retention policies in Cumulocity IoT might have deleted old data. On the other side, data which will definitely be irrelevant for further analysis should not be included in the offloading process.
You may have stored complex data using JSON fragments as an additional column in a Cumulocity IoT collection. As described in section Configuring offloading jobs, you can add additional columns so that they are included in the offloading process. Within these additional columns, you can apply functions to decompose the fragments into flat data.
Writing these functions is often an iterative process that requires multiple adaptations of the underlying logic. Leverage the Dremio SQL editor and define a dummy offloading configuration which moves a small portion of the data into the data lake for testing purposes. You can use the filter predicate to retrieve such a portion of the data; see below for time filter examples. Then you can open the table created by the offloading configuration with Dremio; using Dremio’s SQL editor, you can develop the extraction logic. When your decomposition logic for your additional columns is complete, you can copy the column transformations and use them to define a corresponding offloading configuration in Cumulocity IoT DataHub. Once that is done, the dummy offloading pipeline can be deleted.
When defining an offloading configuration, you can define an additional filter predicate to filter out unwanted entries in the offloading process.
Depending on the collection, you can use different time filters. All collections support creationTime which represents the timestamp when the entity was persisted by the platform (UTC timezone). Mutable entities (alarms, events, inventory) also support lastUpdated which is the timestamp when the entity was last changed (UTC timezone). time is the application timestamp written by the client; it is supported in alarms, events, and measurements.
The below time filters are examples only; you can use much more complex or simpler combinations with a mixture of AND/OR-connected conditions.
Alarms/events To offload all alarms or events which have the application time set to between 2020-02-08 14:00:00.000 and 2020-02-08 15:00:00.000, use:
src."time"."date" >= {ts '2020-02-08 14:00:00.000'} AND
src."time"."date" <= {ts '2020-02-08 15:00:00.000'}
To offload all alarms or events which were persisted after 2020-02-08 15:00:00.000, use:
src."creationTime"."date" > {ts '2020-02-08 15:00:00.000'}
Restricting the offloading to alarms and events last modified before 2020-02-08 14:00:00.000, use:
src."lastUpdated"."date" < {ts '2020-02-08 14:00:00.000'}
Inventory To offload all data which was persisted between 2020-02-08 14:00:00.000 and 2020-02-08 15:00:00.000, use:
src."creationTime"."date" >= {ts '2020-02-08 14:00:00.000'} AND
src."creationTime"."date" <= {ts '2020-02-08 15:00:00.000'}
or, to offload all data that was last updated after 2020-02-08 14:00:00.000, use:
src."lastUpdated"."date" > {ts '2020-02-08 14:00:00.000'}
Measurements To offload all data with application time between 2020-02-08 14:00:00.000 and 2020-02-08 15:00:00.000, use:
src."time"."date" >= {ts '2020-02-08 14:00:00.000'} AND
src."time"."date" <= {ts '2020-02-08 15:00:00.000'}
or, to offload all data received by the platform after 2020-02-08 14:00:00.000, use:
src."creationTime"."date" > {ts '2020-02-08 14:00:00.000'}
To filter by current critical alarms, use:
status != 'CLEARED' AND severity = 'CRITICAL'
To filter by position, provided the field c8y_Position exists, use:
src.c8y_Position.lat > 49.8146 AND src.c8y_Position.lat > 8.6372
To filter by text, use:
text LIKE '%Location updated%'
To limit devices to a specific firmware version, provided the field c8y_Firmware exists, use:
src.c8y_Firmware.version='v1.32'
To limit the offloaded inventory objects to devices, use:
convert_from(convert_to("_fragments", 'JSON'), 'UTF8') LIKE '%"c8y_IsDevice"%'
Main use case of Cumulocity IoT DataHub is to offload data from the internal Cumulocity IoT database to a data lake and query the data lake contents afterwards. In some use cases, Cumulocity IoT DataHub is required to query additional data which is not kept in the Cumulocity IoT platform. For a cloud environment, the additional data must be provided as Parquet files and must be located in the data lake as configured in the initial configuration of Cumulocity IoT DataHub. The Parquet files must not be stored in folders that are used as targets for offloadings as this could corrupt offloading pipelines of Cumulocity IoT DataHub (if the schema doesn’t match with the schema of the Parquet files created via offloading jobs). In addition, the Parquet files must be compliant with the Dremio limitations for Parquet files.
For a dedicated environment, the additional data can be located somewhere else, provided it can be accessed via Dremio, for example, in a relational database. For performance and cost reasons, however, data and processing should always be co-located.
If you want to combine your offloaded IoT data with the new, additional data, you can define a join query in Dremio and store the query as a view. The view can then be queried like any other table in Dremio and provides the combined data.
Cumulocity IoT DataHub offloads IoT data into a data lake. Within this process, the original data is transformed into a relational format and finally stored in files, using the Apache Parquet format. Each offloading configuration has a unique folder in the data lake, which is referred to as target table. The files in that folder are organized in a folder hierarchy based on temporal information. In order to ensure an efficient and in particular correct querying of the data, the files in the data lake must not be modified.
In rare cases, however, the modification of the files is required. You might either want to drop old data or delete one or more columns. First step is to stop and delete the offloading configuration associated with this target table. Next, you can either externally rewrite the data or use Dremio’s CTAS query feature to query the data from this target table, filter obsolete data, and use projections to skip unwanted columns. The query results must be written to a new folder of the data lake. To make the folder accessible as a table in Dremio, promote the folder to a dataset. Then, you can delete the old folder from the data lake. Next, you have to define a new offloading configuration which uses the new folder name as target table name. Define the same filter criteria and columns as in the CTAS query to ensure that the data has the same format. Save the offloading configuration, select the append mode for storing the data, and activate the offloading.
It must be emphasized that this use case is not officially supported by Cumulocity IoT DataHub. While there is nothing wrong in particular with rewriting data (or importing legacy data this way), there is a high risk that the manually created files are not compliant to the required table schema and thus offloading additional data to the target table would not work, i.e., the corresponding offloading pipeline would be broken. In particular, one must be careful to use the correct data type (TIMESTAMPMILLIS) for all timestamp columns (time, timeWithOffset, creationTime, creationTimeWithOffset).